Ha senso pagare 16 volte di più per il modello AI migliore?

Stai pagando per un modello AI senza sapere se ne vale la pena? Tre approcci, stesso brief, costi misurati al centesimo. Haiku con Self-Refine batte Sonnet su quasi tutto, spendendo il 90% in meno.
Tutti usano l’AI. Quasi nessuno sa cosa sta pagando.
ChatGPT, Gemini, Claude.ai: belli, comodi, e progettati per nasconderti tutto quello che conta. Temperatura, token, selezione del modello. Spariti, dietro un’interfaccia pulita che non ti fa domande.
Chi usa le API invece vede tutto. E cambia tutto.
Ho costruito un playground in Blazor per testarlo sul serio. Stesso brief, tre approcci diversi, ogni parametro misurato. Quello che ho trovato non me lo aspettavo.
Due cose da capire prima di tutto
La temperatura non è un’astrazione. È matematica.
Quando scrivi un prompt, il modello sceglie le parole successive in base a probabilità. La temperatura modifica quella distribuzione:
Frase: “Le Marche sono una regione…”
"bellissima" 40% | "affascinante" 35% | "piccola" 15% | altre 10%
Temperatura 0.1 → quasi sempre "bellissima"
Temperatura 0.7 → bilancia le prime 2-3 opzioni
Temperatura 1.0 → anche "piccola" ha chance realeBassa temperatura: risposte prevedibili. Sempre il percorso più sicuro. Alta temperatura: combinazioni che non ti aspetti. Da lì nascono le frasi che ti sorprendono davvero.
I token non sono parole.
Sono frammenti. Il modo in cui il modello legge il testo:
"inaspettatamente" → [inas][pett][ata][mente] = 4 token
"beautiful" → [beautiful] = 1 tokenParole rare e lunghe costano di più. L’italiano costa leggermente più dell’inglese. Ogni token, input e output, ha un prezzo che si somma chiamata dopo chiamata.
Adesso arrivano i test.
Stesso brief, tre approcci
Brief identico: “Scrivi uno slogan per il turismo nelle Marche.”
Sistema prompt uguale per tutti. Temperatura 0.7. Max 800 token. Conversazione pulita prima di ogni test.
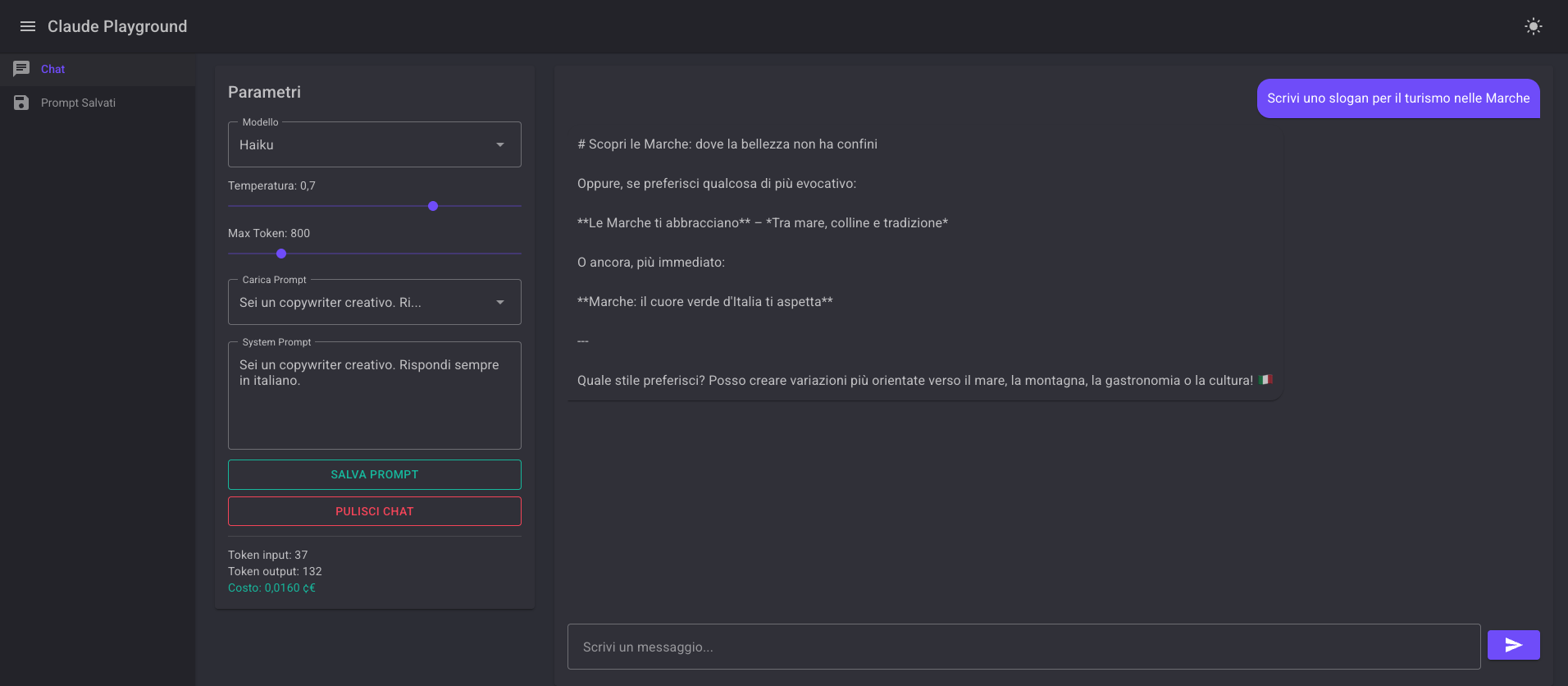
Haiku base, primo test
Modello: Claude Haiku 4.5. System prompt: “Sei un copywriter. Rispondi in italiano.”
Output: “Scopri le Marche: dove la bellezza non ha confini”
Token input: 37 · Token output: 132 · Costo: 0,0160¢
Funziona. Ma potrebbe essere l’Umbria. La Toscana. L’Abruzzo. Non c’è niente che appartenga solo alle Marche.
Haiku con Self-Refine, secondo test
Stessa configurazione. In più, ho aggiunto un meccanismo di autovalutazione al prompt:
Prompt Self-Refine:
Scrivi uno slogan per il turismo nelle Marche.
Poi valutalo da 0 a 10 su:
- Originalità: non è una frase già sentita?
- Impatto emotivo: colpisce davvero?
- Specificità: vale solo per le Marche, non per qualsiasi regione?
Se il totale è sotto 21/30, riscrivilo migliorando i punti deboli. Mostrami solo il risultato finale con il punteggio raggiunto.
Output: “Nelle Marche, le Storie Respirano Ancora”
| Criterio | Punteggio |
|---|---|
| Originalità | 8/10 |
| Impatto emotivo | 9/10 |
| Specificità | 8/10 |
| Totale | 25/30 |
Token input: 308 · Token output: 162 · Costo: 0,0257¢
Completamente diverso. “Respirano ancora” porta continuità storica, richiama i borghi medievali. Non funziona per la Toscana. Non funziona per la Sicilia. È delle Marche.
Sonnet base, terzo test
Modello: Claude Sonnet 4.5. System prompt identico al primo test.
Output: “Marche: plurale di meraviglia”
Token input: 34 · Token output: 185 · Costo: 0,2647¢
Un gioco strutturale sul nome della regione, grammaticalmente già al plurale. Mare, colline, borghi, arte, gastronomia: tutto in due parole. Haiku non ci era arrivato. Nemmeno con il Self-Refine.
I numeri
| Approccio | Output | Costo | Salto qualitativo |
|---|---|---|---|
| Haiku base | Generico, intercambiabile | 0,0160¢ | baseline |
| Haiku + Self-Refine | Specifico, emotivo | 0,0257¢ | +60% costo, ~10x qualità |
| Sonnet base | Creativo, strutturale | 0,2647¢ | +1554% vs Haiku base |
Il dato chiave: Haiku + Self-Refine produce output paragonabili a Sonnet con il 60% in più di costo, non il 1554%. Per la maggior parte dei task, è la scelta migliore.
Cosa mi porto a casa
Il modello costoso non è sempre la risposta.
Haiku con Self-Refine costa il 60% in più rispetto al prompt base. La qualità su molti task (riassunti, copy, risposte strutturate) diventa paragonabile a Sonnet. Per la maggior parte dei casi d’uso reali, quella è la scelta giusta.
Sonnet ha una marcia diversa.
“Plurale di meraviglia” non è solo un buon slogan. È creatività strutturale, un gioco linguistico che richiede comprensione profonda. Hai bisogno di quel tipo di elaborazione? Sonnet giustifica il costo. Non ne hai bisogno? Stai pagando per qualcosa che non usi.
Il contesto non è solo memoria. È un parametro attivo.
Questa l’ho scoperta mentre testavo, non era nei piani. Sonnet, con le conversazioni precedenti in cronologia, produce output influenzati da quello che ha già visto. Non è un bug: è come funzionano i transformer. Il contesto modifica attivamente le probabilità dell’output.
In pratica: pulire la conversazione tra un test e l’altro non è un dettaglio, è metodologia. E nelle applicazioni reali, progettare cosa entra nel context window (lunghezza, rilevanza, ordine) è importante quanto il prompt stesso.
Quello che nessuno ti dice
Tutti ottimizzano i prompt. Quasi nessuno capisce cosa succede sotto.
Quali parametri esistono. Cosa fanno matematicamente. Quanto costano le proprie scelte.
La differenza tra chi usa l’AI e chi la usa bene non è l’abbonamento premium. È sapere cosa stai comprando. Il resto è matematica.
Adesso lo sai.
Nel prossimo esperimento
Self-Refine ha funzionato bene in questo test, ma è solo una delle tecniche possibili. Nel prossimo articolo confronto Self-Refine con altre strategie di prompting, usando Sonnet come giudice per valutare gli output di Haiku. Stessi dati, stessa metodologia, risultati a confronto.